AI创业公司的试金石测试
现在没有什么比说你正在建立一个由人工智能驱动的公司或在 GPT4之上更酷的了。但仅仅冷静是不够的。Jack Dorsey 并没有通过说他们正在 Heroku 上建立一个社交媒体网站来为 Twitter 筹集资金。
当Spanning Labs(Drew的公司)正在构建web3基础设施时,我们发现自己不断需要解释我们不是在寻找问题的技术,而恰恰相反。太多的人花费了太多的时间来构建和投资 web3技术,而不是商业。我们今天在生成性人工智能领域看到了类似的模式。
生成AI是一套强大的工具集。它确实改变了游戏规则。但它并不是终点。
这是一把双刃剑: 在人工智能中构建从来没有这么容易过。从(巨大的)好处来看,这意味着我们现在可以把以前不可能的商业想法(或者以前只是线性可扩展的)转变成伟大的、有回报的投资。现有的公司也在利用人工智能建立新的效率,让他们走得更远、更快。这真是太令人兴奋了。不利的一面是: 还有很多新的垃圾需要筛选。
我们最近参加了一个演示日,有三家公司听起来很有前途——然后我们看了看他们刚刚在上面构建了开源库。现在,与构建在开源项目之上的周末项目相比,了解什么是困难的、独特的和可防御的可能是棘手的。创始人和投资者在评估下一代人工智能公司时,需要回答几个试金石般的问题,尤其是在指数增长和达成共识的时刻。
幸运的是,如果你知道在哪里寻找,有一些方法,一个小团队可以建立一些硬件,独特的,并在人工智能今天防御。因此,我们(摩根和德鲁; 是的,我们是兄弟姐妹)在最近的一次家庭晚宴上集思广益,为创始人和投资者编写备忘录——以及危险信号——这些创始人和投资者正在分别推销和评估在生成性人工智能领域建立的新创业公司。
只有人工智能
首先,最简单也是最重要的一点,如果你在你的项目简介中去掉了所有关于AI的引用,这仍然是一个好的商业模式吗?
AI可能对你解决问题或者扩大解决方案至关重要,但在这个测试中,请将其视为一个黑箱。如果你正在打造一款用户喜欢并且除了AI以外还有其他防御性的产品,恭喜你。
专注于底层酷炫AI如何与核心商业价值主张相关。“ChatGPT for X”并不是业务,X才是业务。从那里你可以使用已经验证过的系统和方法来评估X。X的市场足够大吗?人们愿意为X付费吗?X有某种防御性吗?
如果你正在构建的产品的质量在很大程度上依赖于生成式AI,那么其他有权访问基础模型的人(也就是所有人)可以表现得同样出色。另一方面,如果你的用户体验无与伦比,因为你比任何人都更了解你的终端用户,你可能正在找到一些什么。
好生意就是好生意。
你的正确率是多少?
AI模型会出错。他们是对问题的概率性解决方案。在大多数LLM的情况下,他们是在猜测下一个最可能的单词。这意味着他们会虚构事实、得出错误的结论,甚至撒谎。随着模型变得更聪明,注意力窗口变得更大,这个问题正在得到改善,但它总会是一个问题。
对你来说,这意味着几件事。首先,考虑你的产品在任务失败的情况下仍然可以提供多大的价值。一个直接向病人提供医疗建议的聊天机器人需要基本完美的正确性标准。一个向医生提供医疗建议的聊天机器人只是他的众多工具之一,要求就相对较低。确保你在考虑你的标准是什么,并且你在为正确的用户提供正确的产品。
专注于正确的行业和用户角色甚至可以将这个问题转化为优势。在一些创意领域,这些虚构的表达可能是有价值的,因为那里没有绝对的“错误”答案。
自动驾驶汽车行业在这个正确性问题上花费了大量时间,并为复杂的模型和系统解决它提供了框架。这通常被称为你的操作设计域(ODD)。通过限制你的AI的ODD,验证你的流程的正确性就变得容易得多。对于自动驾驶汽车来说,这意味着限制车辆在非常具体的路况、地图和场景下行驶,并模拟数百万公里的行驶距离。
这种方法的最简单的例子是一个 LLM,其 ODD 经过验证为零。无论你向模型提出什么问题或任务,它都会简单地回应,它不知道如何回答或继续。“我不知道”并不特别有帮助,但至少它从来不会错!
正如唐纳德·拉姆斯菲尔德所说:“存在已知的未知;也就是说,我们知道有一些事情我们不知道。但也有未知的未知——我们不知道我们不知道的事情……后者往往是最难的那些。”
如果你能定义所有的“已知”并建立防护栏以防止任何“未知的未知”,那么你就可以在特定的使用场景下实现高水准的正确性。
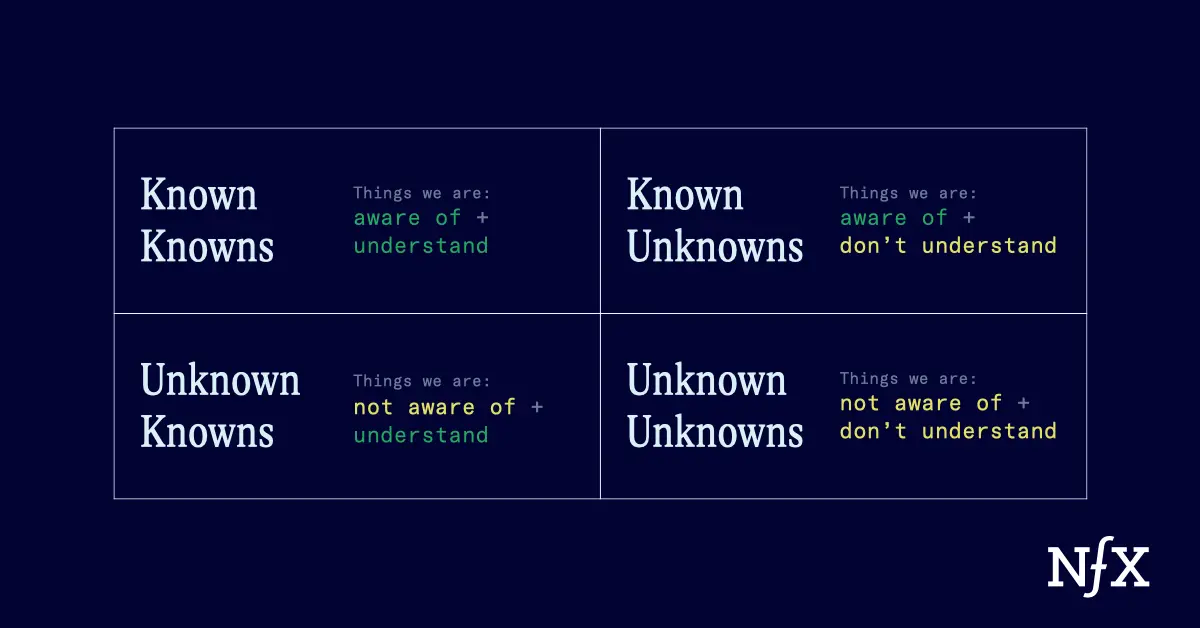
这并不容易,而且非常依赖具体情况,但是有可能定义一个ODD并将你的产品限制在该ODD之内,使得那些需要高正确性的、范围明确的使用场景的业务相当独特。
区别你的AI流水线
我们正越来越深入到基础模型称王的世界。如果你没有数十亿美元,你不应期望能构建并保持在AI研究的前沿。
这意味着你应该专注于围绕这些基础模型可以建立的东西以及如何优化它们。
请记住,基础模型只是基础。在基础模型推理的周围有许多领域,你可以在你的AI流水线中构建出坚实的差异化。
一些例子:
-
为正确的任务选择正确的基础模型;如GPTNeox将信息总结并输入到GPT3的上下文窗口中,可以优化性能和基础设施成本。
-
通过自定义嵌入的提示工程和预处理数据,显著提升特定生成任务的性能。
-
后处理结果以强制执行你的ODD的范围。
-
细调基础模型以适应特定数据集,从而获得独特的性能。
-
强大的基础设施支持端到端的验证流水线,允许快速测试,迭代和改进被集成到你的公司的流水线中。
评估AI创业公司的团队
首先:不要按照炒作来招聘。
创始人,考虑一下,你可能更需要招聘在思科有10年经验的基础设施工程师,而不是斯坦福炙手可热的新ML博士。我们到目前为止讨论的大部分关于构建差异化的内容实际上并不真的需要一堆研究为主的ML工程师。
别误会,你需要你的内部专家能读懂最新的论文,并将技术融入你的产品。我们不会撒谎;现在,那个ML博士的招聘可能会让你更容易进行早期融资。但是你如何快速并且良好地融入这些变化通常只取决于良好的基础设施。关键的基础设施招聘将使构建和维护一个前沿的产品和可持续的业务变得更容易。
在显眼和可持续之间找到平衡是很困难的。能够进行新的研究并为提升AI能力做出贡献是很好的,但是没有一个非常大的研究团队,将其转化为可重复的过程是困难的。
对于创始人和投资者来说,重要的教训是,你应该把有良好基础设施工程经验的人视为一些最好的生产ML工程师。事实上,有经验在产品化系统上工作的ML工程师可能花了大量的时间在基础设施上。
另一个教训是,在生成AI的时代,你的创业公司可能并不需要你想象中的那么多人。而你可能会对你实际需要的人的类型感到惊讶。

一些好的试金石测试
这里有一些具体的问题,你应该自问,而投资者肯定也会问你。
问:基础模型会取代你的业务吗?
- 你在什么上花费时间,而这些在引入新的基础模型时只会变得更好?
- 你在围绕对基础模型的调用建立你的AI流水线时,有哪些是你可以申请专利的?
问:如果别人有相同的想法,并且能够访问到相同的模型(他们确实可以),你打算构建什么独特的、困难的、他们不能做的事情?
- 这种差异性是否存在于预处理、后处理、测试流水线等中…
- 或者它是否存在于你的技术栈之外,比如你的用户体验、商业模型或问题焦点?
问:你需要多频繁地给你的用户提供正确的答案,才能使产品可行?
- 你如何定义你的ODD,并围绕你的已知未知和未知未知建立防护栏?
- 你是如何测量正确性的?
问:用户完成与你的核心产品相同的任务需要多长时间,以ChatGPT+的方式?
- 这只是知道正确的提示的问题吗?
- 它是否需要大量的设置,比如复制和粘贴其他文档?
- 这是否可能?
问:你如何验证你的AI流水线的改变对你的产品有所提升,这个验证需要多长时间?
- 你使用什么指标来衡量改进,这个指标有什么固有的偏见?
- 你的过程是手动的还是自动的?
- 如果是自动的,你的验证流水线是否有语义含义/当你的指标变化时,是否清楚原因?
问:为什么你们是做这个的正确团队?
- 你对你的客户人物画像了解得有多深?
- 你有建立和优化生产ML基础设施的经验吗?
- 你是否了解如何评估和测试AI模型的优点和缺点?