做了一个随机视频的网页
去年,我在GPT 4 的帮助下,做了个“每日一问“的网页。当时本想使用framer来做的,但发现后台数据库不方便,便采用了supabase做问题数据库,然后让chatGPT写的网页代码,代码托管到了阿里云服务器。
不过,虽然当时完成了自己的第一个编程作品,但效果并不好,数据不够,并不能实现问题随机以此出现。而且,网页加载非常慢。
时间到了今年,博客网站需要付费,我考虑找个便宜的平台自建。最后考虑用网络上的astro模版,然后自己修改相应的页面设置。
但修改设置对于来我说也是有一些难度的,而且我一直有个问题没有解决,就是如何将之前博客的json文件导入到新博客项目里。
1
这个问题,困扰了我很长一段时间。
因为astro是可以通过github部署到vercel上的,所以,我刚开始以为只需要把json文件上传到github就可以了。但这显然是错误的。
之前我将这个困惑提交给chatgpt,它说要转化格式,然后给我一段代码,让我放到github项目里。我按照逻辑去做了,然后我发现python文件并没有转化。因为部署到vercel上,并不会主动执行python,除非你增加触发条件。当然,作为编程小白,当时并不知道这些。
然后,在claude3.5出现后,我将同样的问题提交给了它。我发现它更擅长理解问题,或者说,能引导用户提出正确的问题,因为它会在每次回答后,补充可能存在其他的问题,或者其他资料。
在摸索一段时间后,我意识到首先需要将json文件转成符合项目要求的markdown格式,然后将markdown格式的文字放在合适的地方,这样部署的项目才能将这些文章呈现出来。
当然,这两步我是前后才意识到了,花了3-4天的摸索。
2
解决了导入之前博客文章的问题之后,就是网站设置了,包括导航页面,网站域名之类的,这些并不算复杂,配置也相对简单。并没有花费我很多时间。
重点是我既然利用了astro自建了博客,那么我是否可以按照自己的想法来建立自己的网页,比如带用时间轴的动态,比如将之前的项目都弄过来。
这时,我刚好看到了一个随机视频的项目,我好奇检查了网页代码,然后我发现它是将视频链接放在
一个开源的google slide项目里,然后网页代码加载了视频链接,然后实现了随机视频的项目。
然后,我就觉得我可以通过supabase或者其他数据库完成类似的项目,部署到自己的网页上?
这样的想法,激励着我。然后我将这样的想法提交给了claude。
3
我直接把该网页的代码复制给claude,让其在我的博客上实现相关页面,这个对于claude来说很简单。
但在做的过程中,我考虑使用notion作为数据库,也就是我在notion上建立一个数据表格,然后通过notion api将其同步到我的博客上。这个比我之前用supabase更为了省事,但我需要重新了解下大概逻辑。
但这个对于claude而言,并不是很困难。claude让我新建一个notionApi.js 与getvideo.js
import { Client } from '@notionhq/client';
console.log('NOTION_API_KEY:', import.meta.env.NOTION_API_KEY ? 'Set' : 'Not set');
console.log('NOTION_DATABASE_ID:', import.meta.env.NOTION_DATABASE_ID);
const notion = new Client({ auth: import.meta.env.NOTION_API_KEY });
const databaseId = import.meta.env.NOTION_DATABASE_ID;
export async function getVideos() {
try {
console.log('Fetching videos from Notion...');
console.log('Using database ID:', databaseId);
if (!databaseId) {
throw new Error('NOTION_DATABASE_ID is not set');
}
const response = await notion.databases.query({
database_id: databaseId,
});
console.log('Notion response:', JSON.stringify(response, null, 2));
if (!response.results || response.results.length === 0) {
console.log('No results found in the Notion response');
return [];
}
const videos = response.results.map(page => {
console.log('Processing page:', JSON.stringify(page, null, 2));
return {
id: page.id,
title: page.properties.Title?.title[0]?.plain_text || 'Untitled',
link: page.properties.Link?.url || '',
author: page.properties.Author?.rich_text[0]?.plain_text || 'Unknown',
nugget: page.properties.Nugget?.rich_text[0]?.plain_text || '',
tags: page.properties.Tags?.multi_select?.map(tag => tag.name) || []
};
});
console.log('Processed videos:', videos);
return videos;
} catch (error) {
console.error('Error fetching videos from Notion:', error);
return [];
}
}
import { getVideos } from '../../utils/notionApi';
export async function get() {
try {
const videos = await getVideos();
return new Response(JSON.stringify(videos), {
status: 200,
headers: {
'Content-Type': 'application/json'
}
});
} catch (error) {
return new Response(JSON.stringify({ error: 'Failed to fetch videos' }), {
status: 500,
headers: {
'Content-Type': 'application/json'
}
});
}
}
这个过程中,我学习了noiton api相关知识,然后js代码全靠claude,其中因为claude并不能看notion数据库,所以在抓取数据库内容的时候,出现了一些问题。claude的逻辑,是通过错误提示来确定错误的原因,然后进行修改。
这让我初步完成了项目。
4
但我发现完善项目的欲望是强大的。
因为参考里的视频链接都是youtube的,然后使用的都是嵌入式的链接,但我自己直接把youtube链接添加到数据库,却发现并不能在网页上呈现出来。所以,我需要让数据库里的链接,都能被代码处理。不仅是youtube,还有bilibili等。
这个过程并不算复杂,只是bilibili的iframe格式并不好用,直接用iframe并不能被检测出来。所以,代码需要检测bilibili链接,然后做单独处理。
function getEmbedCode(link) {
// 检测 Bilibili 链接
const bilibiliRegex = /https?:\/\/(www\.)?bilibili\.com\/video\/(BV[\w]+)/;
const bilibiliMatch = link.match(bilibiliRegex);
if (bilibiliMatch) {
const videoId = bilibiliMatch[2];
return `<iframe src="//player.bilibili.com/player.html?bvid=${videoId}&page=1" scrolling="no" border="0" frameborder="no" framespacing="0" allowfullscreen="true"> </iframe>`;
}
// YouTube 嵌入代码
if (link.includes('youtube.com') || link.includes('youtu.be')) {
return `<iframe src="${link}" frameborder="0" allow="autoplay; fullscreen; picture-in-picture" allowfullscreen></iframe>`;
}
// Vimeo 嵌入代码
if (link.includes('vimeo.com')) {
return `<iframe src="${link}" frameborder="0" allow="autoplay; fullscreen; picture-in-picture" allowfullscreen></iframe>`;
}
// 对于其他未知的链接,我们可以尝试直接嵌入,或者显示一个链接
return `<a href="${link}" target="_blank" rel="noopener noreferrer">Watch Video</a>`;
}
另外一个问题是,视频播放器尺寸的问题。最好的效果是视频播放器尺寸是固定的。然后所有视频都是以这个尺寸播放。但刚开始的效果是,在未点击播放按钮的时候,视频播放器尺寸特别小,只有点击播放后,才会调整成更大尺寸。
为了解决这个问题,我跟claude 好几次对话,才真正解决这个问题
function adjustVideoSize() {
const streamContainer = document.getElementById('streamContainer');
const iframe = document.getElementById('stream').querySelector('iframe');
if (iframe) {
const containerWidth = streamContainer.clientWidth;
const targetHeight = containerWidth * (9 / 16);
iframe.style.width = `${containerWidth}px`;
iframe.style.height = `${targetHeight}px`;
}
}
<style>
#stream iframe {
width: 100%;
height: 100%;
aspect-ratio: 16 / 9;
}
</style>
但在这个过程中,又发现了另一个问题。
编程就是发现问题,解决问题呀。
bilibili链接一旦播放,会直接跳转到bilibili的网站,这显然并不是我想要的。所以,我在解决播放尺寸和对齐问题后,又开始处理bilibili链接播放问题。
这又让我花费了不少时间,感觉做一个项目,总有新问题。
5
这些问题解决后,我想调整页面内容宽度,但发现改完之后,很多需要调整,我就放弃了。
然后,
我想,我在telegram频道里有个值得一看的视频,其实都可以同步到notion里,然后在网站上呈现。这个想法,让我可以了解之前一直感兴趣的tg bot项目,我需要通过tg bot来抓取telegram更新的内容,然后通过noiton api来同步到notion数据库。
这个过程中,我花了一些时间了解频道CHAT_ID,然后让telegram里的信息能够按要求同步到noiton数据库里。
这一步虽然对我比较陌生,但claude执行起来,却没有什么问题。只要我想好抓取所有内容还是之后更新的内容,抓取的数据处理与notion相符合就行。
稍微比较麻烦的是,视频链接里标题的获取,youtube最后采用了YoutubeDL这个项目,而bilibili在几次尝试后,我选择了放弃,还是手动填写吧。
def get_video_title(url):
ydl_opts = {
'quiet': True,
'no_warnings': True,
}
with YoutubeDL(ydl_opts) as ydl:
try:
info = ydl.extract_info(url, download=False)
return info.get('title', '未知标题')
except DownloadError as e:
logging.error(f"无法获取视频标题: {url}, 错误: {e}")
return '未知标题'
6
解决了上面的问题之后,这个项目基本是完成了。但还有一个问题。将tg频道的内容同步到notion如何自动执行。
最后,想到了github action完成。
name: Sync Telegram to Notion
on:
schedule:
- cron: '0 0 * * *' # 每天运行一次
workflow_dispatch: # 允许手动触发
jobs:
sync:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run sync script
env:
TELEGRAM_TOKEN: ${{ secrets.TELEGRAM_TOKEN }}
CHAT_ID: ${{ secrets.CHAT_ID }}
NOTION_TOKEN: ${{ secrets.NOTION_TOKEN }}
DATABASE_ID: ${{ secrets.DATABASE_ID }}
run: python channel2n.py
这样其每天便会自动同步到notion。
7
至此,我便完成了将telegram频道内容同步到notion数据库,然后将notion数据库里的内容同步到自己博客。
下面是项目页面。
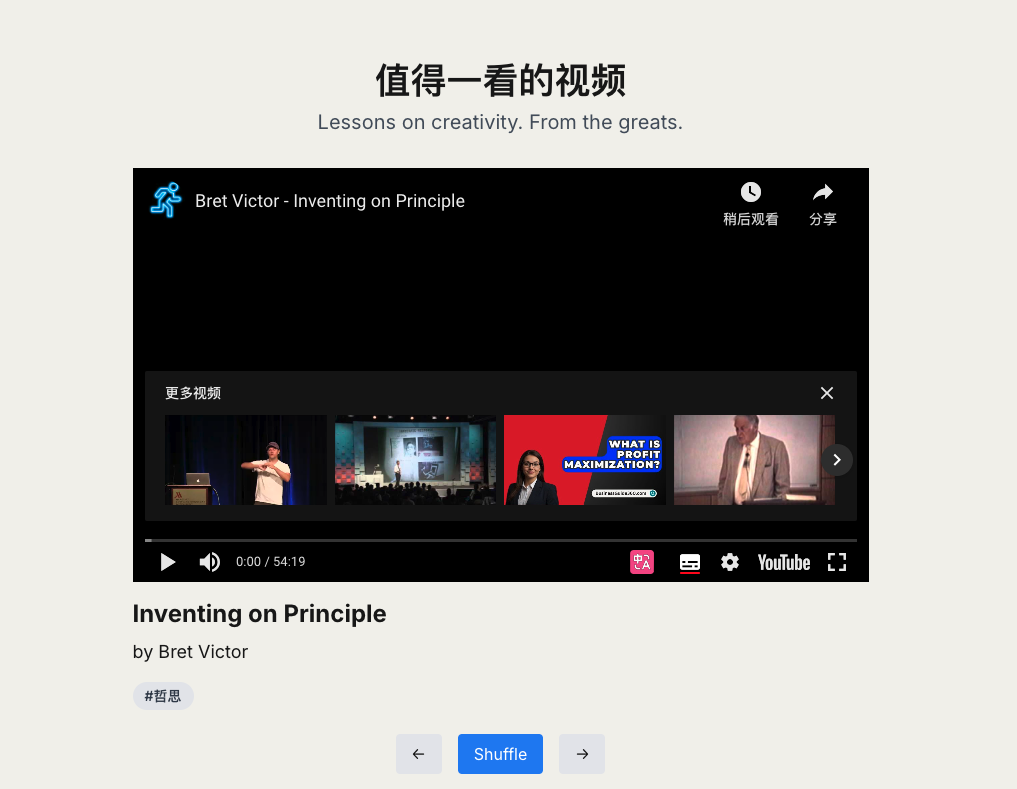
个人感觉还不错,然后在做这个过程中,我对编程也有了更多理解,虽然很多代码是靠claude写的,但断断续续也理解了一些逻辑,勉强能看懂代码了。然后我也理解和学会如何使用github托管本地代码了。
8
这个项目把我带入到了编程的世界,后面我也将会分享一些其他依靠AI实现的项目。